
【AI活用】robots.txtの書き方|パラメータ付きURLを除外する実例つき

業務効率化

「robots.txtを編集したいけど、書き方を間違えてサイト全体がインデックスから消えたら怖い…」
オウンドメディア担当者なら、一度は感じたことがある不安ではないでしょうか。
本記事では、AIとの実際のやり取りをもとに、パラメータ付きURLを除外するrobots.txtを完成させるまでの流れを解説します。
基本構文・配置場所・WordPress(All in One SEO)での設定・Search Consoleでの確認方法までセットで紹介するので、コピペで使える実例として活用してください。
目次
そもそもrobots.txtとは?

robots.txtとは、Googleなどの検索エンジンのクローラーに対して「このURLは見に来なくていい」と伝えるためのテキストファイルです。サイトのルートディレクトリに設置することで、クロールしてほしくないページやディレクトリを指定できます。
ここでよく混同されるのが「noindex」との違いです。robots.txtはあくまでクロール(Googleのボットの巡回)を制御するもので、インデックス(Googleのデータベースへの登録)を直接制御するものではありません。
すでにインデックス済みのURLをrobots.txtでブロックしても、すぐに検索結果から消えるわけではない点やあくまで指示出しをするため必ずしもインデックスを拒否できるわけではない点に注意が必要です。
また、書き方を1文字間違えるとサイト全体がクロール拒否される可能性もあるため、慎重に編集する必要があります。
robots.txtがない場合はどうなる?
robots.txtがなくてもサイトは正常に動作します。
ファイルが存在しない場合、クローラーはすべてのURLがクロール許可されていると判断するため、インデックス(Googleのデータベースへの登録)自体には影響しません。
ただし、パラメータ付きURLの重複や管理画面などインデックスさせたくないページが増えてくると、クロールの最適化や重複コンテンツ対策の観点から設置が推奨されます。
特にECサイトや会員制サイトのようなデータベース型サイトなど、メディアでパラメータ付きURLが多発する環境では、robots.txtで整理しておくことでSEO効果の改善が期待できます。
robots.txtの基本構文と書き方

robots.txtの書き方はシンプルで、基本となるディレクティブ(命令)はたった4つだけです。
まずはこれらを押さえれば、ほとんどのケースに対応できます。
robots.txtを構成する4つの基本ディレクティブ

robots.txtで使う主なディレクティブは以下のとおりです。それぞれの役割を理解しておきましょう。
- User-agent:対象とするクローラーを指定(例:「*」はすべてのクローラー)
- Disallow:クロールを拒否するURLパスを指定
- Allow:Disallowで拒否したパスの中で、例外的に許可するパスを指定
- Sitemap:XMLサイトマップの場所を伝える(任意)
最もシンプルな記述例は次のようになります。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap.xmlDisallowは全てのページをクロール拒否する書き方
サイト全体のクロールを拒否したい場合は、Disallowにスラッシュ1つを指定します。
User-agent: *
Disallow: /
この記述はステージング環境や開発中のテストサイトなど「絶対にインデックスさせたくない環境」で使う書き方です。
本番サイトに誤って設置すると、検索流入が完全に消えるリスクがあるため、公開時には必ず削除する運用ルールを徹底してください。
Disallowで複数のURLを指定する書き方
複数のURLをクロール拒否したい場合は、1行1ディレクティブを原則として記述します。カンマ区切りや改行なしの一括指定はできません。
User-agent: *
Disallow: /private/
Disallow: /tmp/
Disallow: /draft.htmlディレクトリ単位・ファイル単位のほか、ワイルドカード(「*」は任意の文字列、「$」はURLの末尾、「?」はクエリ文字列の開始)を使えば柔軟なパターン指定も可能です。GoogleとBingはこれらのワイルドカードをサポートしています。
Disallowの記述で空白を入れてはいけない理由
robots.txtでよくある初歩的なミスが「Disallow:」の後に何も書かずに空欄にしてしまうパターンです。
Disallow: (これが空欄)
この記述は「何もブロックしない」=「すべて許可」と解釈されます。意図とは逆に動作してしまうため要注意です。
robots.txtの配置場所
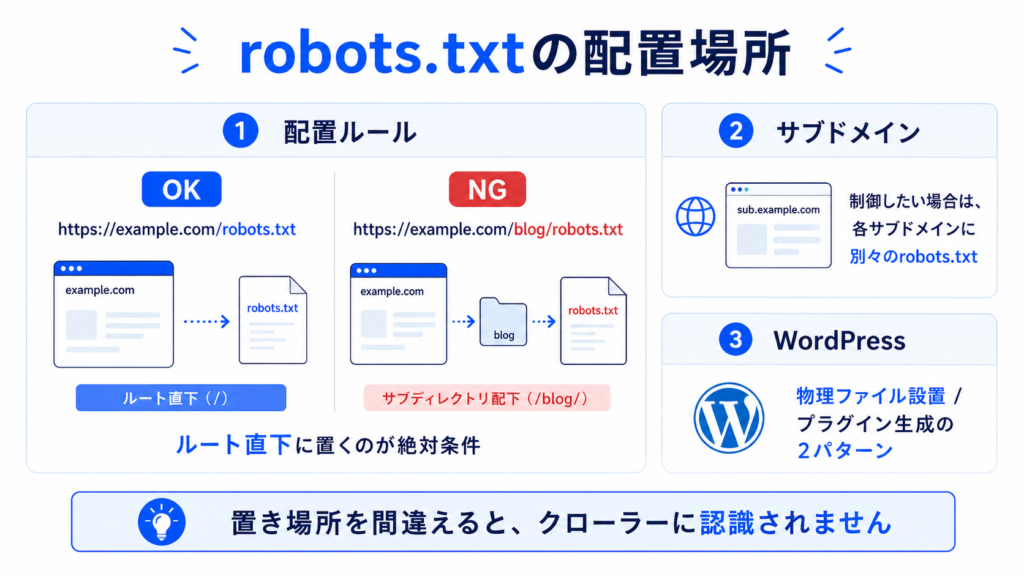
robots.txtは、ドメインのルートディレクトリ直下に配置するのが絶対条件です。
https://example.com/robots.txt ← OK
https://example.com/blog/robots.txt ← NG(クローラーは認識しない)サブディレクトリやサブドメインの配下に置いても、クローラーはrobots.txtとして認識しません。
サブドメインごとに制御したい場合は、それぞれのサブドメインのルートに別々のrobots.txtを設置する必要があります。
なおWordPressの場合は、サーバーに物理ファイルを置く方法のほか、SEOプラグイン(All in One SEOなど)を使い、動的に生成する方法もあります。プラグインを使う場合の手順は本記事の後半で解説します。
【実例】AIと進めるrobots.txtの書き方|パラメータ付きURLを除外する
ここからは、実際にClaudeとのやり取りでパラメータ付きURLを除外するrobots.txtを完成させた事例を紹介します。
AIに丸投げするとどうなるのか、最終的にどう絞り込むのかという実務の流れがそのままわかるように解説します。
やりたいこと パラメータ付きURLをクロール拒否する
今回の対象サイトでは、全393URLのうち34件にパラメータ付きURL(「?」を含むURL)が存在していました。
広告のクリックIDやUTMトラッキング、サイト内検索など、本来インデックスさせる必要のないURLです。
これらを放置すると、同一コンテンツが複数URLで存在する重複コンテンツ扱いとなり、クロールバジェットの浪費やSEO評価の分散につながります。実データから検出された主なパラメータは以下の通りです。
| カテゴリ | 検出されたパラメータ |
| 広告クリックID | fbclid(Facebook)/gclid(Google広告)/yclid(Yahoo広告)/fpc |
| UTMパラメータ | utm_source/utm_medium |
| 独自トラッキング | argument/ref/forcedcta/dmai |
| サイト内検索 | s |
| 並び替え・ページング | sort/page/paged/ls など |
AIへの最初の指示と「やりすぎ問題」
最初にAIへ「Excelに入っているパラメータ付きURLを1つずつ個別に記述してほしい」と依頼したところ、AIは検出されたすべてのパラメータを律儀に書き出し、23種類ものDisallowルールを提案してきました。
しかし実データを見直すと、その多くが「同じ1つのURL内で同時に使われている派生パラメータ」だったり、1回しか出現しないケースだったりします。AIにそのまま任せると過剰な記述になりやすく、管理が煩雑になるという典型的な落とし穴です。
ここで人間が判断すべきは、本当に除外が必要なパラメータだけに絞り込む工程です。AIの出力をそのまま採用せず、実データと照らし合わせて削るところは削るという判断が重要となります。
パラメータの絞り込み 先頭に来るパラメータだけ書けばOK
ここで重要なのが、robots.txtで除外を判断するパスは「URLの先頭からの前方一致」で判定されるという仕組みです。つまり、URLの最初に来るパラメータさえ明確にすれば、その後ろにくっついているパラメータも一緒に除外できます。
たとえば次のURLを見てみましょう。
https://example.com/?utm_source=google&utm_medium=cpc&forcedcta=off
このURLは「Disallow: /*?utm_source=」の1行だけで除外できます。先頭の「?utm_source=」がマッチした時点でURL全体がブロック対象になるため、後ろの「&utm_medium=」「&forcedcta=」を個別に書く必要はありません。
「Disallow: /*&forcedcta=」のような『&』始まりの行は不要、ということです。この仕組みを理解すると、記述量を一気に減らせます。
最終的に絞り込んだrobots.txtの実例
実データの34件すべてを除外できることを検証した上で完成したのが、以下の12行のrobots.txtです。
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
# 広告クリックID
Disallow: /*?fbclid=
Disallow: /*?gclid=
Disallow: /*?yclid=
Disallow: /*?fpc=
# UTMパラメータ
Disallow: /*?utm_source=
# 独自トラッキング
Disallow: /*?argument=
Disallow: /*?ref=
Disallow: /*?forcedcta=
# サイト内検索
Disallow: /*?s=
# 並び替え・ページング・フィルタ
Disallow: /*?sort=
Disallow: /*?page=
Disallow: /*?ls=先頭に来るパラメータだけに絞ったことで、23種類だった記述が12行までシンプルになりました。
自社サイトに当てはめる場合は、Search Consoleや解析ツールで実際にどのパラメータが使われているかを確認してから記述するのがポイントです。
AIに任せる範囲と人間が判断する範囲
今回のやり取りで明確になった役割分担は、以下の通りです。
- AIに任せる:構文の正確性、パターンの網羅、コードの整形、URLエンコードの処理
- 人間が判断する:実データの精査、巻き添え除外の可否、運用上の優先度、最終的な絞り込み
AIは網羅的に書き出すのが得意ですが、本当に必要かどうかの取捨選択は人間の役割です。この役割分担を意識すると、AI活用の品質が一段と上がります。
WordPress(All in One SEO)でrobots.txtを設定する方法

WordPressでrobots.txtを設定する最も簡単な方法が、All in One SEOプラグインのインポート機能を使う方法です。物理ファイルをFTPでアップロードする必要はなく、管理画面の操作だけで完結します。
手順は以下の通りです。
- WordPress管理画面で「All in One SEO」→「ツール」を開く
- 「カスタムRobots.txtを有効にする」のトグルをONにする
- ルールビルダー右上の「インポート」ボタンをクリック
- robots.txtテキストを貼り付け」のフィールドに、完成したrobots.txtの中身をコピペ
- 「インポート」ボタンを押すと、ルールビルダーに各行が自動展開される
- 「カスタムRobots.txtプレビュー」で確認し、「変更を保存」をクリック
注意点として、サーバーのルートに静的なrobots.txtファイルが残っているとそちらが優先されてしまいます。
FTP等で確認して古いファイルがあれば削除しておきましょう。また、ルールビルダーはコメント行(#始まりの行)を保存しない仕様ですが、機能上は問題ありません。
robots.txtの確認方法とテスト

robots.txtを設定したら、必ず動作確認をしましょう。
確認方法は3段階に分けて進めるのが確実です。
ブラウザで直接確認する
まず最も簡単なのが、ブラウザのアドレスバーに「https://ドメイン名/robots.txt」と入力してアクセスする方法です。先ほど設定した内容がそのまま表示されればOKです。
表示されない、もしくは古い内容のままの場合は、All in One SEOのプレビュー画面と実際の出力が一致しているか、サーバーに古いrobots.txtが残っていないかを確認してください。
Search Consoleの「robots.txtレポート」で確認する
以前は、robots.txtテスターというツールが用意されていましたが、現在は廃止されrobots.txtレポートに置き換わっています。
Google Search Consoleにログインしたら、対象プロパティを選択し、左メニューの設定を選択肢クロールセクション内にあるrobots.txtのレポートを開きます。
ここで「取得済み」のステータス、前回のクロール日時、エラーや警告の有無を確認できます。
反映が遅いと感じたら、レポート画面の「再クロールをリクエスト」ボタンから再取得を依頼することも可能です。
URL検査ツールで個別URLをテストする
最も重要なのが、URL検査ツールでパラメータ付きURLが実際にブロックされるかを確認する作業です。
Search Console上部の検索ボックスにテストしたいURL(例:「https://example.com/?ref=lgo」)を入力し、「公開URLをテスト」をクリックします。結果に「robots.txtによりブロックされています」と表示されればブロック成功です。
逆に、ブロックしたくない通常URLも検査して「クロール許可:はい」になっていることを確認しておくと安心です。なお、インデックス登録のリクエストは今回のようなクロールを拒否する設定では不要です。混同しないよう注意してください。
反映までの時間と注意点
robots.txtの変更がGoogleに認識されるまでは、通常24時間〜数日かかります。
さらに、すでにインデックス済みのパラメータ付きURLが検索結果から消えるには、数週間〜数ヶ月かかることもあります。
急ぎで検索結果から消したい場合は、Search Consoleの「削除」ツール(一時的な削除リクエスト)を併用すると、最長6ヶ月間の非表示が可能です。その間にrobots.txt経由でGoogleが「クロール不可」と認識し、自然にインデックスから外れていく流れになります。
robots.txtに関するよくある質問
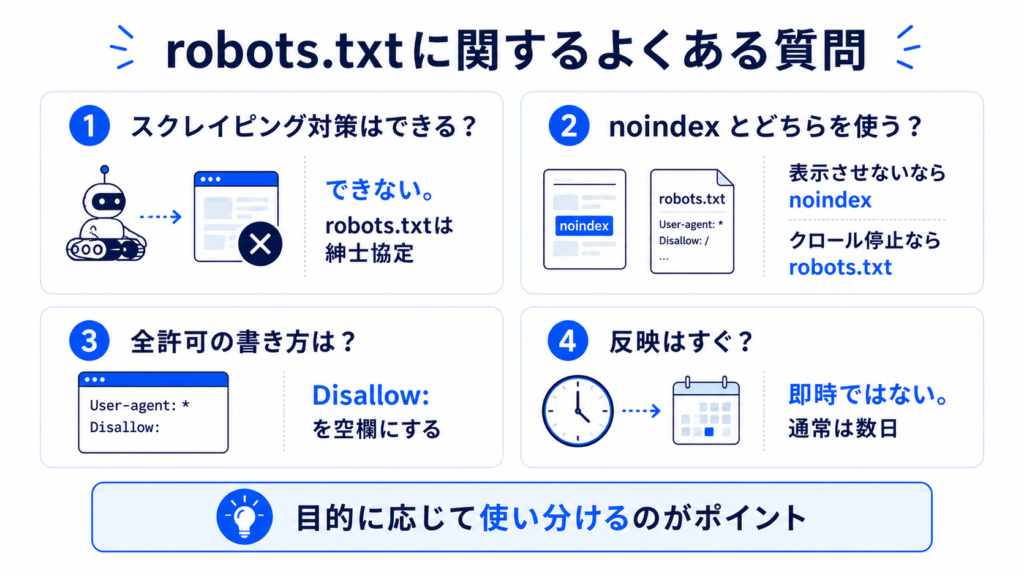
robots.txtでスクレイピング対策はできる?
robots.txtはスクレイピング対策にはなりません。
robots.txtはあくまで紳士協定であり、ルールを守るかどうかはクローラー側の任意です。
GoogleやBingなどの大手検索エンジンは遵守しますが、悪意あるスクレイピングボットは無視してアクセスしてきます。スクレイピング対策には、WAFやアクセス制限など別の仕組みが必要です。
noindexとrobots.txtはどちらを使うべき?
目的によって使い分けが必要です。
検索結果に表示させたくないだけならnoindexメタタグ、クロール自体を止めたいならrobots.txtが適しています。
robots.txtでブロックしてしまうとGoogleがページ内のnoindexタグを読み取れなくなるため、「検索結果から消したい」場合はrobots.txtでブロックせずにnoindexを使うのが正解です。
すべてのページを許可したい場合の書き方は?
すべてのURLをクロール許可するなら、以下のように記述します。
User-agent: *
Disallow:
「Disallow:」の後ろを空欄にすることで「何もブロックしない」=「全許可」を意味します。あるいはrobots.txt自体を設置しなくても、結果として全URLが許可された扱いになります。
robots.txtを編集したらすぐにSearch Consoleに反映される?
即時に反映されるわけではありません。
Googleが次にrobots.txtを取得したタイミングで反映され、通常24時間以内、遅くとも数日以内に認識されます。
Search Consoleの「再クロールをリクエスト」を使えば多少早めることはできますが、必須の操作ではありません。
まとめ
今回はAIとの実際のやり取りをもとに、パラメータ付きURLを除外するrobots.txtの書き方を解説しました。
robots.txtというと「触ると怖い」「専門知識が必要」というイメージがあるかもしれませんが、AIをうまく活用すれば誰でも安全に編集できます。
まずは自社サイトのパラメータ付きURLを洗い出し、本記事の内容を参考に試してみてください。



